LeetCode75(一)
LeetCode75 Day1
1768.交替合并字符串
给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。
返回 合并后的字符串 。
示例 1:
1 | 输入:word1 = "abc", word2 = "pqr" |
示例 2:
1 | 输入:word1 = "ab", word2 = "pqrs" |
示例 3:
1 | 输入:word1 = "abcd", word2 = "pq" |
提示:
1 <= word1.length, word2.length <= 100word1和word2由小写英文字母组成
代码:
1 | char * mergeAlternately(char * word1, char * word2){ |
- 首先,函数通过
malloc动态分配了足够的内存来存储合并后的字符串,这个内存大小是两个输入字符串长度之和加上一个额外的字符用于存储字符串结束的空字符'\0'。 - 接下来使用两个循环变量
i和j来遍历两个输入字符串word1和word2,同时将它们的字符逐个交替放入新字符串ans中。这个过程在循环中进行,直到其中一个字符串的字符遍历完毕。 - 如果其中一个字符串遍历完了而另一个字符串还有剩余字符,那么需要继续将剩余字符添加到
ans中。这部分代码使用了两个if条件来判断哪个字符串有剩余字符,并将剩余字符逐个添加到ans中。 - 最后,确保
ans字符串以空字符'\0'结尾,以符合 C 语言字符串的约定。 - 返回合并后的字符串
ans。
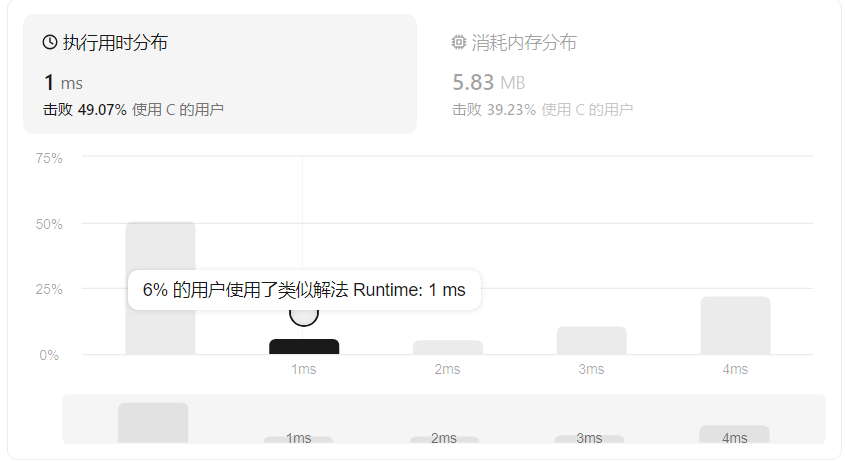
leetcode给出代码运行后的执行时间已经消耗内存,这个时候发现还有一个更快的解决方案:
1 | char * mergeAlternately(char * word1, char * word2){ |
- 首先,通过
strlen函数获取了word1和word2的长度,并分别存储在len1和len2变量中。 - 然后,使用
calloc函数分配了足够的内存来存储合并后的字符串。calloc与malloc类似,都用于动态分配内存,但是calloc在分配内存的同时会将分配的内存块中的每个字节都初始化为零。在这里,分配的内存大小为len1 + len2 + 1,即两个输入字符串的长度之和再加上一个额外的字符\0,用于存储字符串结束的空字符。 - 接下来,使用
for循环遍历合并后的字符串的每个位置。循环变量i用于表示合并后字符串的当前位置,而j和k则分别用于遍历word1和word2。 - 在循环中,通过判断
word1和word2的当前字符是否为\0,即判断是否到达字符串的结束,来决定是否将字符添加到合并后的字符串中。如果word1或word2还有字符未处理,则将其添加到合并后的字符串中,并且i的值递增。 - 最后,确保合并后的字符串以空字符
\0结尾,以符合 C 语言字符串的约定。 - 返回合并后的字符串
result。
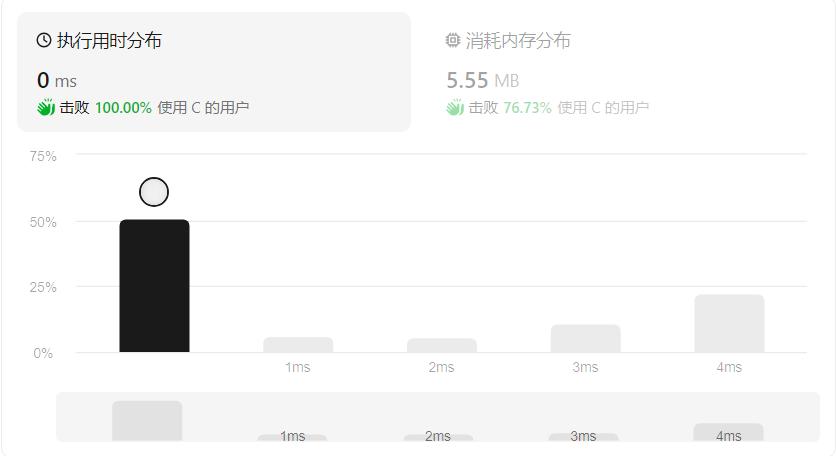
这段代码与之前的代码相比,使用了 calloc 函数分配内存,并且使用了单个循环来遍历两个字符串并将其合并,代码逻辑更加简洁。
相较于第一段代码用了多个for循环,这段代码只需要一个for循环,通过判断字符串是否为’\0’结尾。
1071.字符串的最大公因子
对于字符串 s 和 t,只有在 s = t + t + t + ... + t + t(t 自身连接 1 次或多次)时,我们才认定 “t 能除尽 s”。
给定两个字符串 str1 和 str2 。返回最长字符串 x,要求满足 x 能除尽 str1 且 x 能除尽 str2 。
示例 1:
1 | 输入:str1 = "ABCABC", str2 = "ABC" |
示例 2:
1 | 输入:str1 = "ABABAB", str2 = "ABAB" |
示例 3:
1 | 输入:str1 = "LEET", str2 = "CODE" |
提示:
1 <= str1.length, str2.length <= 1000str1和str2由大写英文字母组成
代码:
1 | char* gcdOfStrings(char* str1, char* str2) { |
- 首先,通过
strlen函数获取了str1和str2的长度,并分别存储在n1和n2变量中。 - 使用
while循环进行迭代处理,直到找到最大公因子或者无法继续进行迭代为止。 - 在每次循环中,通过
strncmp函数比较str1和str2的前n1或n2个字符是否相等,以判断它们是否是共有的前缀或后缀。 - 如果两个字符串的长度相等,并且它们的前
n1个字符相等,则表示整个字符串都是共有的最大公因子,直接返回str1。 - 如果
str1的长度大于str2的长度,并且str1的前n2个字符与str2相等,则将str1的指针向后移动n2个字符,同时更新n1为原来的长度减去n2。 - 如果
str1的长度小于str2的长度,并且str1的前n1个字符与str2相等,则将str2的指针向后移动n1个字符,同时更新n2为原来的长度减去n1。 - 如果以上情况都不满足,则表示没有找到公因子,直接返回空字符串
""。 - 循环继续进行,直到找到最大公因子或者无法继续迭代。
- 返回找到的最大公因子或空字符串。
总的来说,这段代码利用了字符串的前缀和后缀的性质来寻找两个字符串的最大公因子,通过不断地比较和调整字符串的长度和指针位置来达到这个目的。
1 | char* gcdOfStrings(char* str1, char* str2) { |
- 首先,通过
strlen函数获取了str1和str2的长度,并分别存储在len1和len2变量中。 - 使用
while(1)循环进行迭代处理,直到找到最大公因子或者无法继续进行迭代为止。while(1)是一个无限循环,表示会一直执行循环内的代码,直到遇到return语句或者break语句终止循环。 - 在每次循环中,通过
strncmp函数比较str1和str2的前len1或len2个字符是否相等,以判断它们是否是共有的前缀或后缀。 - 如果两个字符串的长度相等,并且它们的前
len1个字符相等,则表示整个字符串都是共有的最大公因子,直接返回str1。 - 如果
str1的长度大于str2的长度,并且str1的前len2个字符与str2相等,则将str1的指针向后移动len2个字符,同时更新len1为原来的长度减去len2。 - 如果
str1的长度小于str2的长度,并且str1的前len1个字符与str2相等,则将str2的指针向后移动len1个字符,同时更新len2为原来的长度减去len1。 - 如果以上情况都不满足,则表示没有找到公因子,直接返回空字符串
""。 - 循环继续进行,直到找到最大公因子或者无法继续迭代。
- 返回找到的最大公因子或空字符串。
这段代码与之前解释的代码逻辑相同,只是将 while 循环的终止条件改为了 while(1),代表无限循环。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 空白!